Abstract
Ensuring safety in dynamic multi-agent systems is challenging due to limited information about the other agents. Control Barrier Functions (CBFs) are showing promise for safety assurance but current methods make strong assumptions about other agents and often rely on manual tuning to balance safety, feasibility, and performance. In this work, we delve into the problem of adaptive safe learning for multi-agent systems with CBF. We show how emergent behavior can be profoundly influenced by the CBF configuration, highlighting the necessity for a responsive and dynamic approach to CBF design. We present ASRL, a novel adaptive safe RL framework, to fully automate the optimization of policy and CBF coefficients, to enhance safety and long-term performance through reinforcement learning. By directly interacting with the other agents, ASRL learns to cope with diverse agent behaviours and maintains the cost violations below a desired limit. We evaluate ASRL in a multi-robot system and a competitive multi-agent racing scenario, against learning-based and control-theoretic approaches. We empirically demonstrate the efficacy and flexibility of ASRL, and assess generalization and scalability to out-of-distribution scenarios.
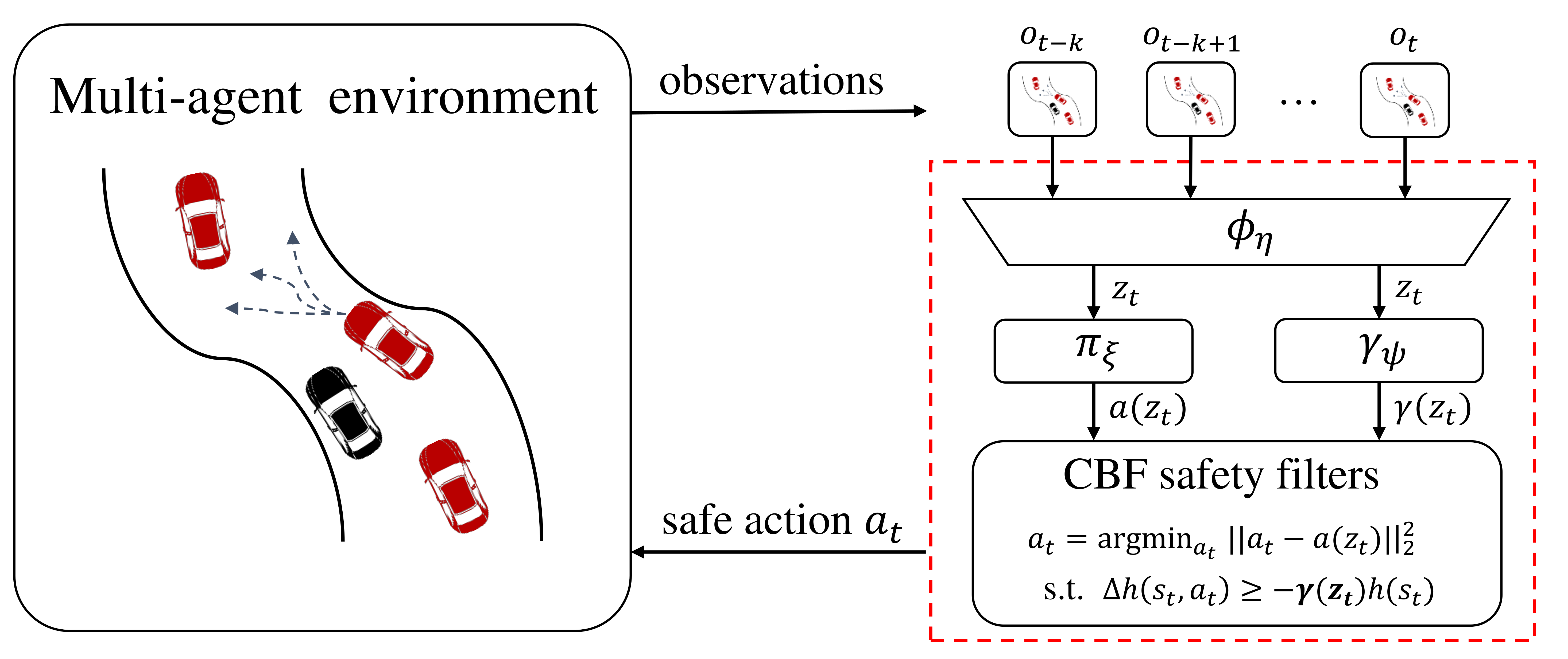
Approach
- We encode a sequence of observations \( o_{t-k}, ..., o_t \) into a latent representation \( z_t \). Then, we feed \( z_t \) into a high-level module that is a multi-head network.
- Using a policy head, we generate the candidate action \( a(z_t) \).
- Using the adaptive safety head, we generate the candidate CBF coefficients \( \gamma(z_t) \).
- The candidate action and CBF coefficients are then given to the low-level module, which computes the safe action \( a_{t} \) executed in the environment.
- We train the high-level module by solving a constrained optimization problem that maximizes the expected return while keeping the cost violations below a desired limit. At each time step, the CBF coefficients adapts to the current state of the environment, to balance safety and long-term performance.
Generalization Evaluation
We evaluate the generalization capabilities of our trained agent in various multi-agent racing scenarios including:- varying the number of agents,
- in-distribution planners with varying velocity profiles, and
- out-of-distribution planners with new strategies and varying velocity profiles.
For each scenario, we sample many starting positions with the ego behind other agents (Figure, top left) and run simulations for 60 seconds. We consider collision or lap completion as termination conditions and measure the final positioning (rank) as common in racing competitions.
BibTeX
@article{berducci2023learning,
title={Learning adaptive safety for multi-agent systems},
author={Berducci, Luigi and Yang, Shuo and Mangharam, Rahul and Grosu, Radu},
journal={arXiv preprint arXiv:2309.10657},
year={2023}
}